Đại Chiến Bán Dẫn 2nm: Chip Venice Của AMD Thách Thức Ngai Vàng NVIDIA

Chào các chuyên gia phần cứng và lập trình viên đám mây! Hôm nay chúng ta sẽ cùng đi sâu vào cấp độ nguyên tử của thế giới bán dẫn để thảo luận về một cột mốc hạ tầng có thật: AMD đã bắt đầu ramp sản xuất CPU EPYC thế hệ 6 mang mã hiệu 'Venice' trên tiến trình 2nm của TSMC.
Vài năm qua, NVIDIA gần như chiếm trọn cuộc thảo luận về accelerator. Nhưng việc AMD đưa Venice lên tiến trình 2nm tiên tiến vẫn rất quan trọng, vì CPU là lớp điều phối dữ liệu, mạng, lưu trữ, bảo mật và orchestration quanh các cụm AI dùng nhiều GPU.
Nhận định cá nhân của tôi: Hệ sinh thái phần mềm CUDA mới là pháo đài thực sự của NVIDIA chứ không chỉ là thông số phần cứng. Nếu AMD không thể làm cho nền tảng mã nguồn mở ROCm của họ mượt mà tương đương, ngay cả chip 2nm Venice cũng sẽ gặp khó khăn lớn trong việc chiếm lĩnh thị phần. Chúng ta hãy cùng phân tích bước đột phá phần cứng này.
Các thông số kỹ thuật: Tại sao 2nm Venice đáng chú ý?
- Ramp sản xuất trên TSMC 2nm: AMD cho biết Venice là sản phẩm HPC đầu tiên bước vào giai đoạn production ramp trên công nghệ 2nm tiên tiến của TSMC.
- Vai trò trong hạ tầng AI: CPU điều phối luồng dữ liệu, mạng, lưu trữ, bảo mật và orchestration quanh các cụm accelerator.
- Tính liên tục của roadmap: AMD cũng nhắc tới "Verano", một dòng EPYC thế hệ 6 tiếp theo với đổi mới bộ nhớ LPDDR cho workload cloud và AI bị giới hạn bởi điện năng.
(Kiến trúc bán dẫn siêu nhỏ gọn 2nm Venice EPYC)
Hướng dẫn hạ tầng: Tối ưu hóa hệ thống đám mây của bạn
- Tránh bẫy độc quyền CUDA (Hardware-Agnostic Code): Hãy sử dụng các engine runtime mở như ONNX Runtime, vLLM, hoặc Triton Inference Server để code của bạn chạy mượt mà trên cả GPU NVIDIA lẫn GPU AMD Instinct.
- Tối ưu hóa dung lượng bộ nhớ (Model Quantization): Áp dụng kỹ thuật nén lượng tử (Quantization FP8 hoặc INT4) để chạy mô hình vừa vặn trên các cấu hình server rẻ tiền hơn.
- Sử dụng Kubernetes để phân phối tài nguyên động: Cài đặt hệ thống tự động chuyển các tác vụ xử lý nền sang các node chip AMD rẻ hơn vào giờ thấp điểm.
- Lưu trữ đệm tại Client: Giảm tải cho server bằng cách xử lý cache ngay tại Client để tiết kiệm băng thông và chi phí điện toán.
Nguồn: thông cáo ramp sản xuất Venice của AMD.
Trải nghiệm của bạn thế nào? Bạn đã từng tích hợp chip AMD Instinct vào hệ thống AI của mình chưa, hay CUDA vẫn là lựa chọn độc tôn không thể thay thế? Hãy cùng thảo luận nhé!
Sẵn sàng sắp xếp tri thức với AI?
BrainMap tự động phân loại ghi chú, khám phá kết nối và xây dựng đồ thị tri thức cá nhân. Miễn phí — không cần thẻ tín dụng.
Dùng thử miễn phíBài viết liên quan
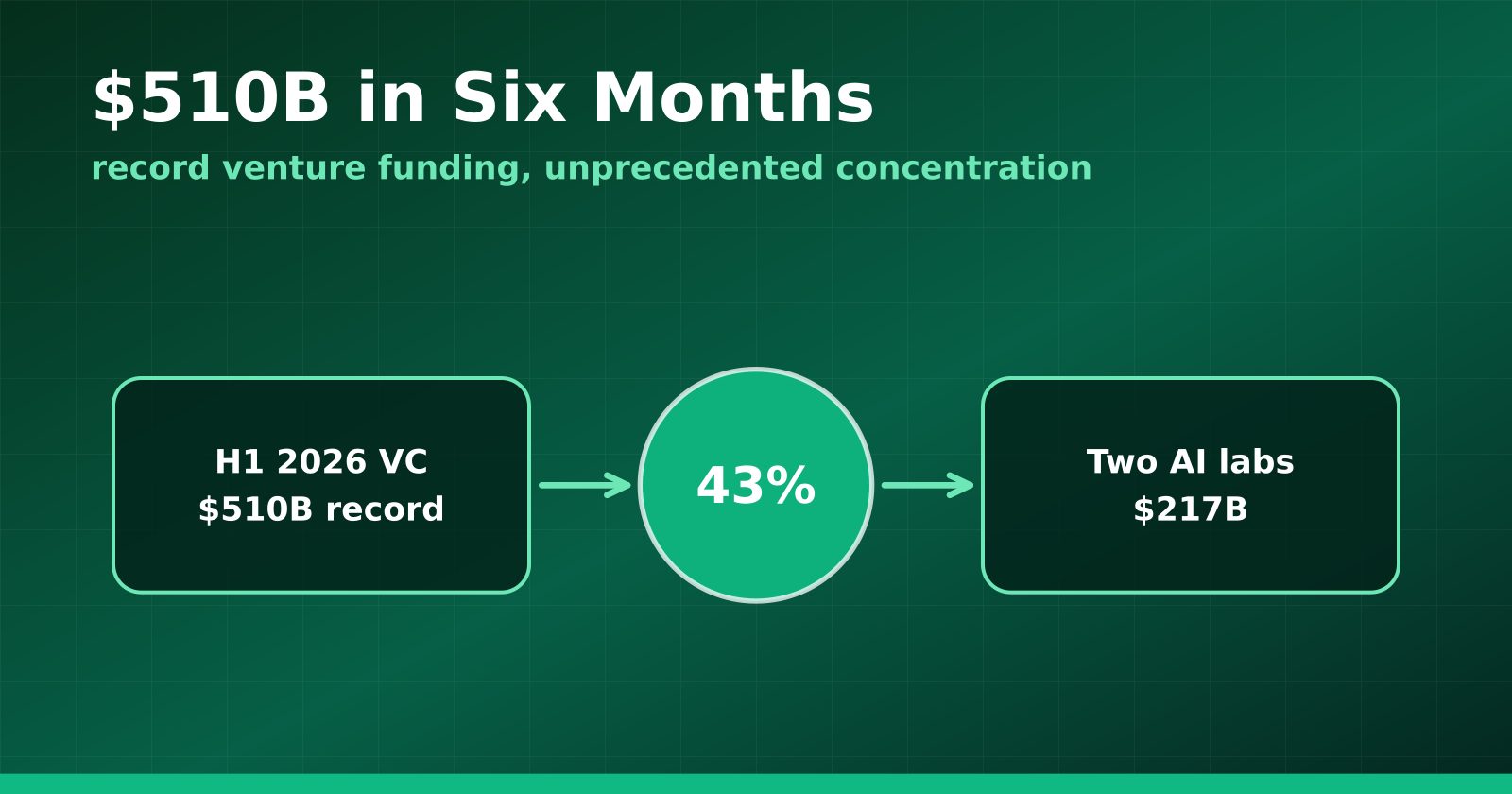
510 tỷ đô đổ vào startup nửa đầu 2026 — gần một nửa chảy về hai cái tên
Báo cáo bán niên của Crunchbase: vốn mạo hiểm toàn cầu lập đỉnh lịch sử, nhưng riêng OpenAI và Anthropic đã hút 217 tỷ đô, tức 43% tổng vốn của cả thế giới startup.
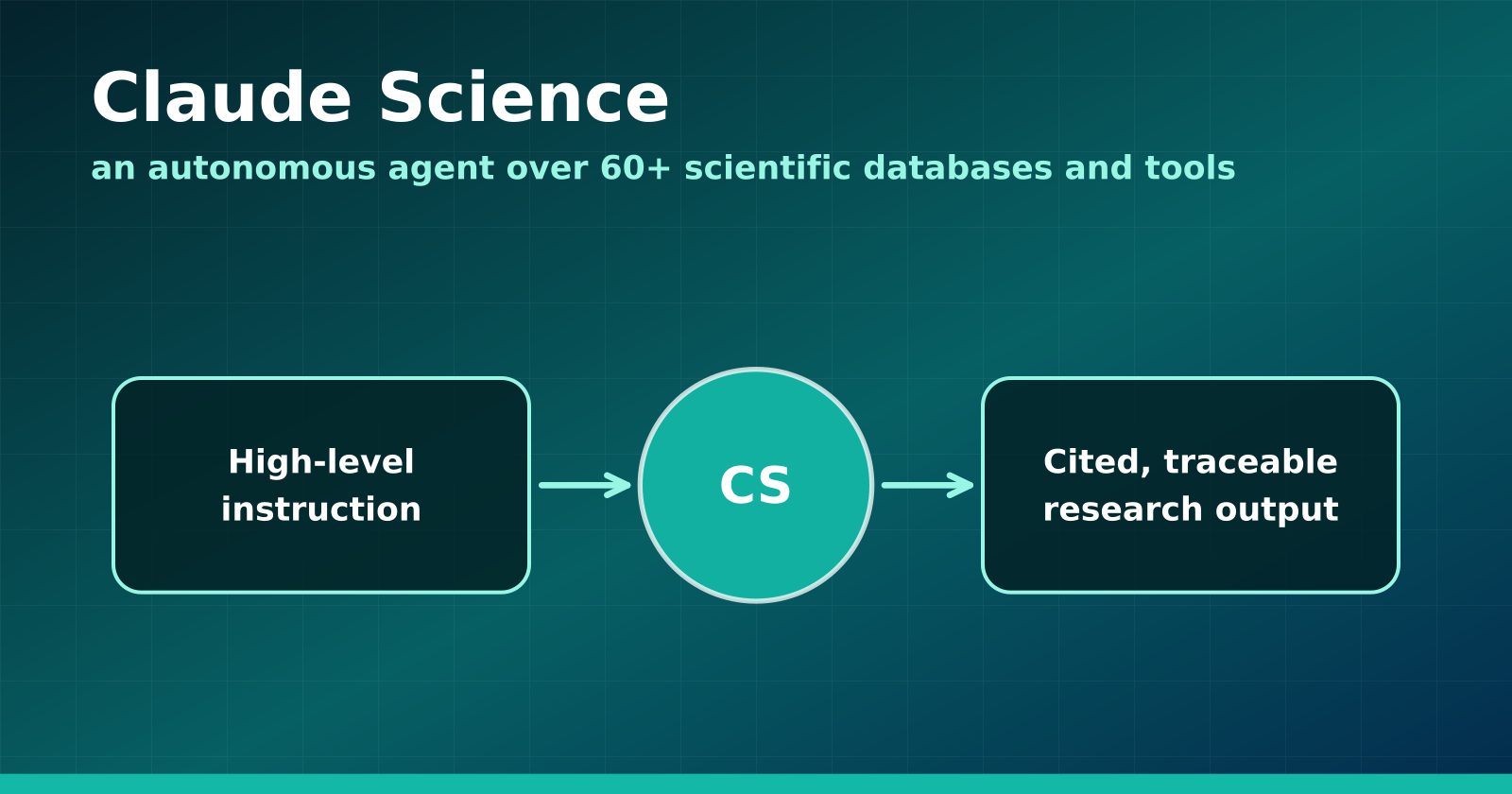
Claude Science: khi agent ngồi vào bàn làm việc của nhà khoa học
Sản phẩm chủ lực mới của Anthropic nối hơn 60 cơ sở dữ liệu khoa học vào một agent tự làm việc. Hãng còn tự dùng nó để đi tìm thuốc cho các bệnh hiếm.
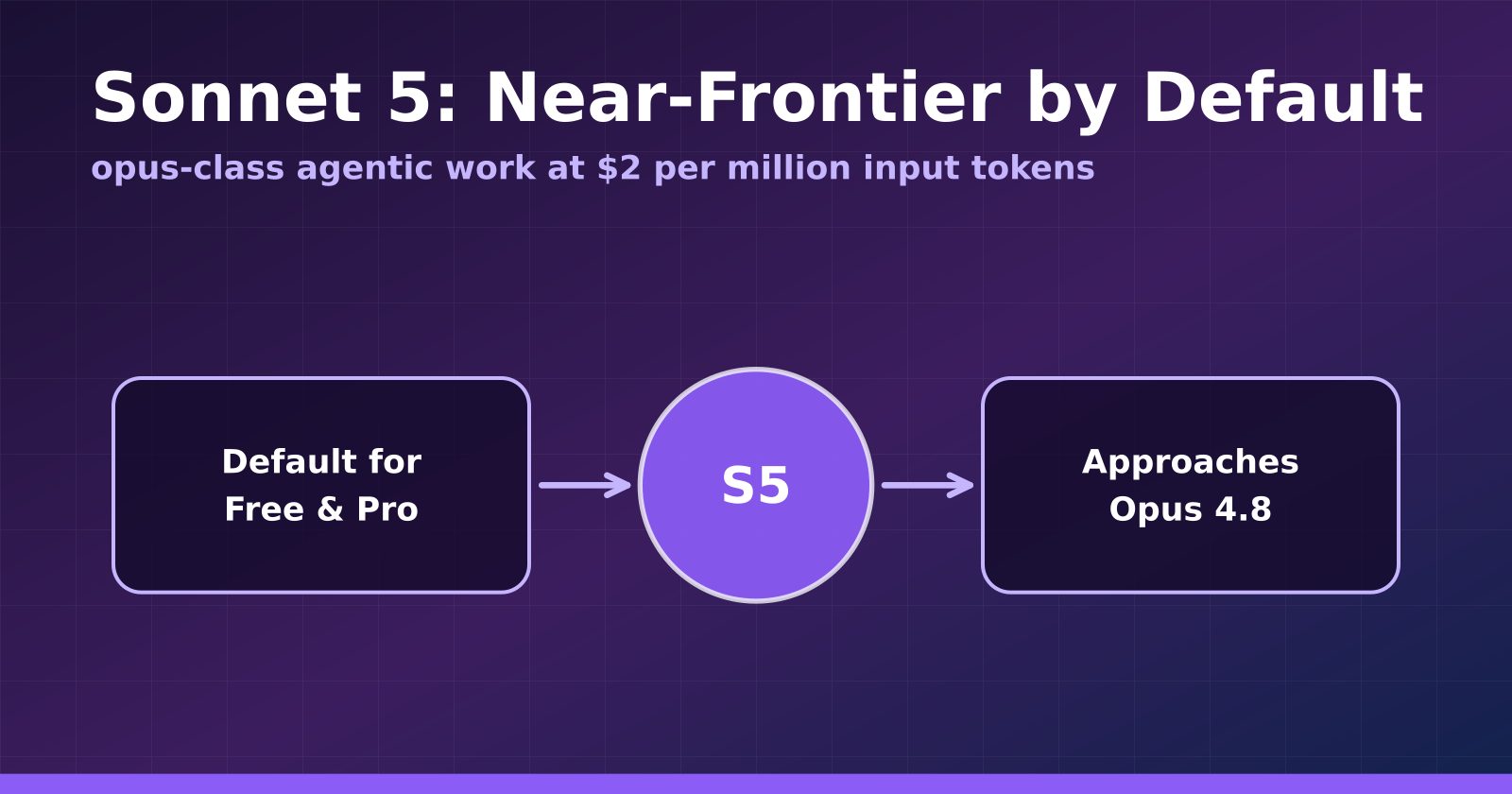
Claude Sonnet 5: mạnh gần bằng Opus, giá chỉ 2 đô
Anthropic vừa tung Sonnet 5 với sức mạnh tiệm cận Opus 4.8 nhưng giá khuyến mãi chỉ 2 đô mỗi triệu token. Người dùng Free và Pro được chuyển sang mô hình mới ngay lập tức.