Silicon Wars: Inside AMD's 2nm 'Venice' EPYC and the Threat to NVIDIA's AI Dominance

Hello hardware enthusiasts and cloud builders! Today we are sliding down into the atomic scale of AI engineering to discuss a real infrastructure milestone: AMD has begun ramping production of its 6th Gen EPYC processors, codenamed 'Venice', on TSMC's 2nm process.
For the past couple of years, NVIDIA has dominated the accelerator conversation. But AMD’s transition to TSMC’s advanced 2nm process for Venice matters because CPUs still coordinate data movement, networking, storage, security, and orchestration across AI data centers.
My personal perspective: NVIDIA's CUDA software ecosystem remains their true defensive moat, not just their hardware specs. If AMD cannot make their open-source ROCm platform equally friction-free for developers, even 2nm Venice will struggle to steal market share. Let's look at the specs of this silicon-level breakthrough and explore a guide on how to choose and optimize your cloud infrastructure.
The Specs: Why 2nm Venice Matters
To understand the leap, we have to look at what AMD has actually announced:
- Production ramp on TSMC 2nm: AMD says Venice is the first HPC product to enter production ramp on TSMC's advanced 2nm technology.
- AI infrastructure role: The CPU coordinates data movement, networking, storage, security, and orchestration around accelerator-heavy clusters.
- Roadmap continuity: AMD also points to "Verano" as a follow-on 6th Gen EPYC processor with LPDDR-focused memory innovations for power-constrained cloud and AI workloads.
(AMD 2nm Silicon EPYC Venice Wafer Microarchitecture)
Cloud Guide: How to Optimize Your AI Infrastructure Today
While you might not be buying Venice CPUs directly, you will be renting them on AWS, Azure, or GCP:
- Avoid CUDA-Lock (Write Hardware-Agnostic Code): Stop relying strictly on NVIDIA-proprietary CUDA APIs. Use open-source runtime engines like ONNX Runtime, vLLM, or Triton Inference Server.
- Optimize Memory Alignment: FP16 model weights are massive. Use weight quantization (FP8 or INT4) to fit larger models into cheaper hardware tiers with negligible loss in accuracy.
- Use Kubernetes for Dynamic Compute Allocation: Set up cloud clusters that dynamically shift background tasks to AMD instances if they are cheaper during off-peak hours.
- Implement Local Cache Mechanics: Reduce server load by caching on the client-side, ensuring we only call server APIs when absolutely necessary.
Source: AMD's Venice production ramp announcement.
What is your experience? Have you successfully integrated AMD Instinct or EPYC chips in your AI pipelines, or is CUDA still too dominant to ignore? Let's talk in the comments!
Ready to organize your knowledge with AI?
BrainMap automatically classifies your notes, discovers connections, and builds your personal knowledge graph. Free to start — no credit card required.
Start for FreeRelated Articles
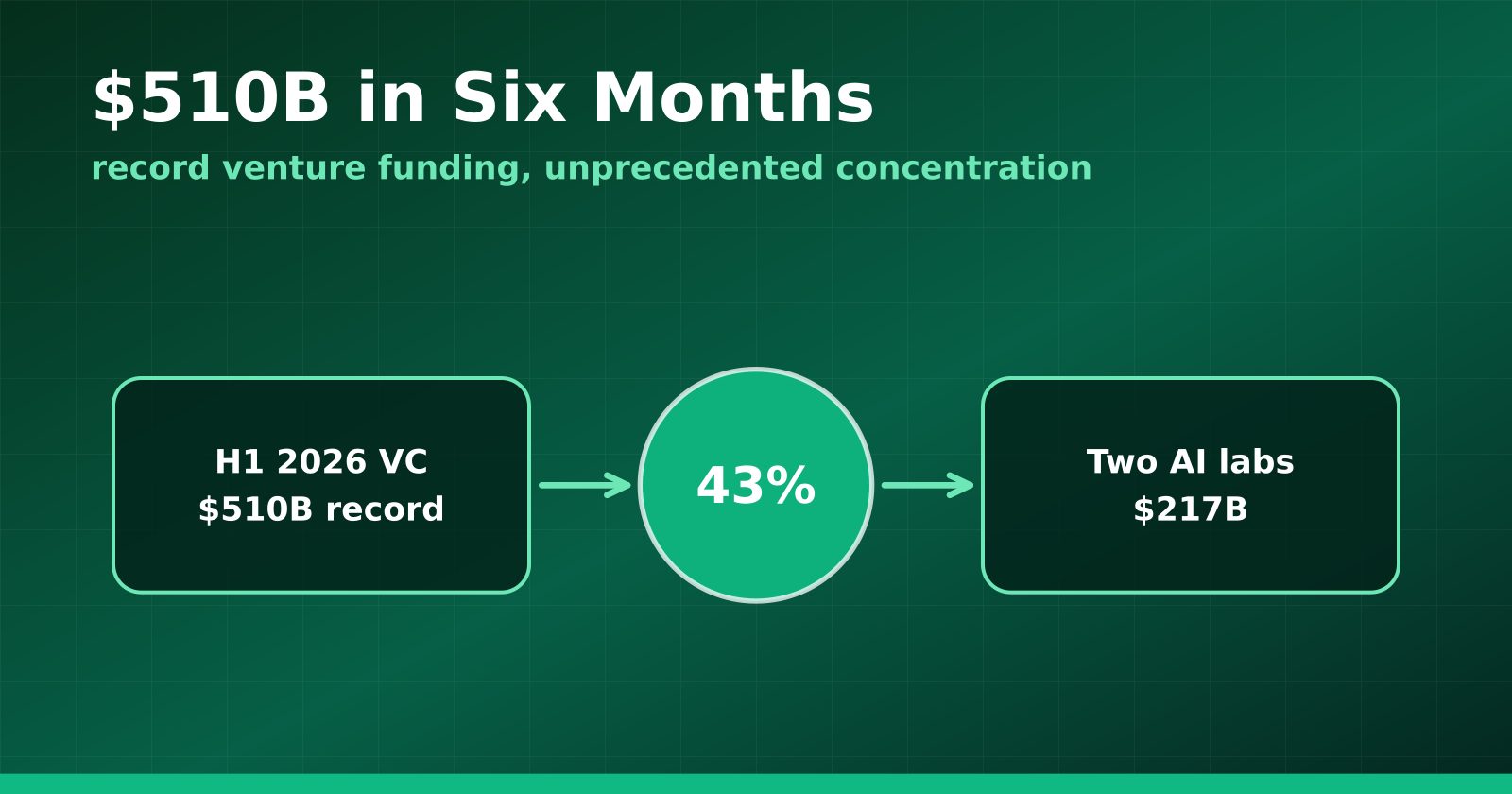
H1 2026 Venture Funding Hit a Record $510B — and Two AI Labs Took 43%
Crunchbase's half-year report shows global VC at an all-time high, with OpenAI and Anthropic alone absorbing $217 billion and AI claiming roughly two-thirds of all deployment.
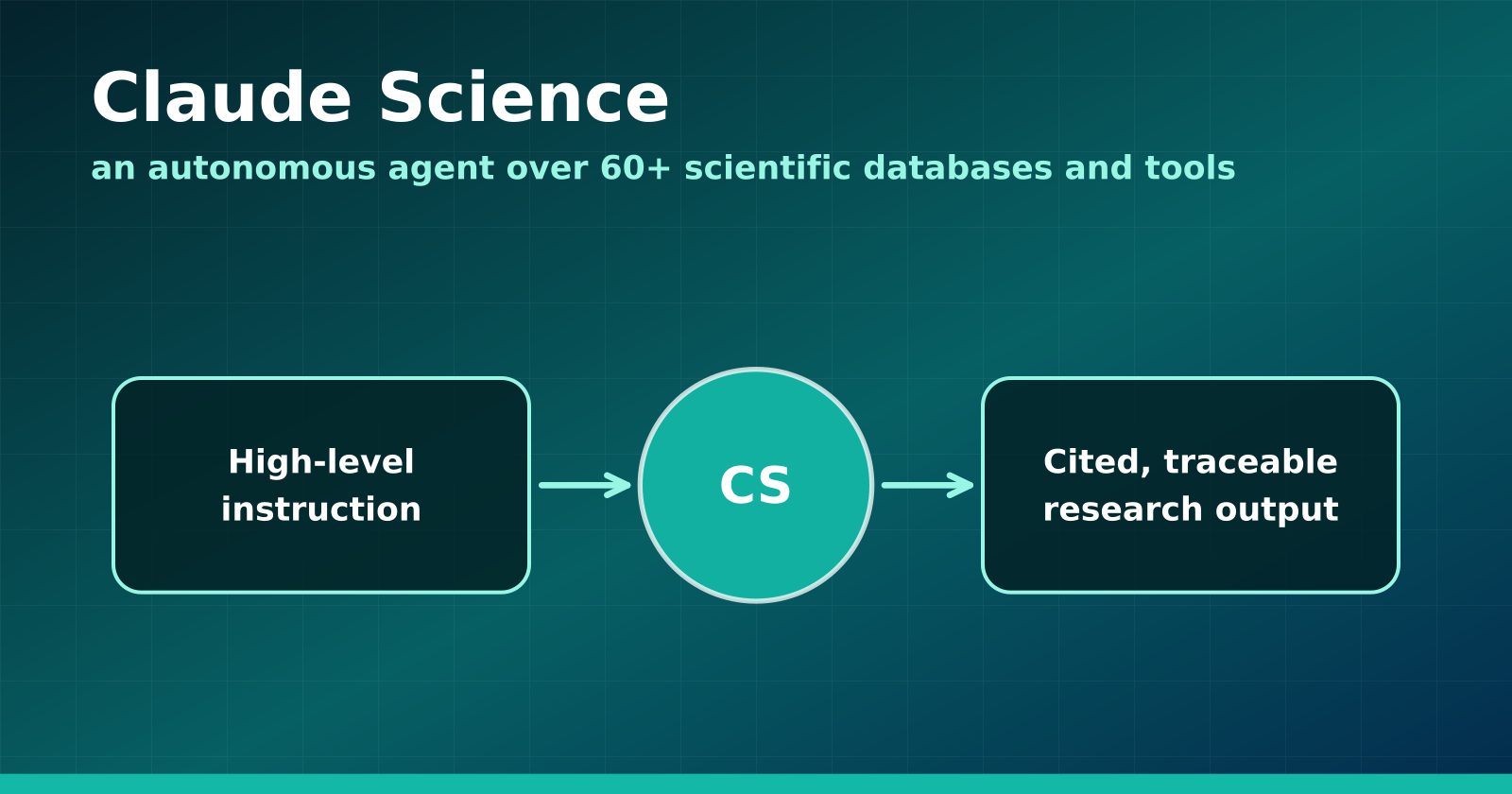
Claude Science Turns the Research Workbench Into an Agent Surface
Anthropic's new flagship product wires 60+ scientific databases and computation tools into an autonomous research agent — and Anthropic is using it to hunt drugs for neglected diseases.
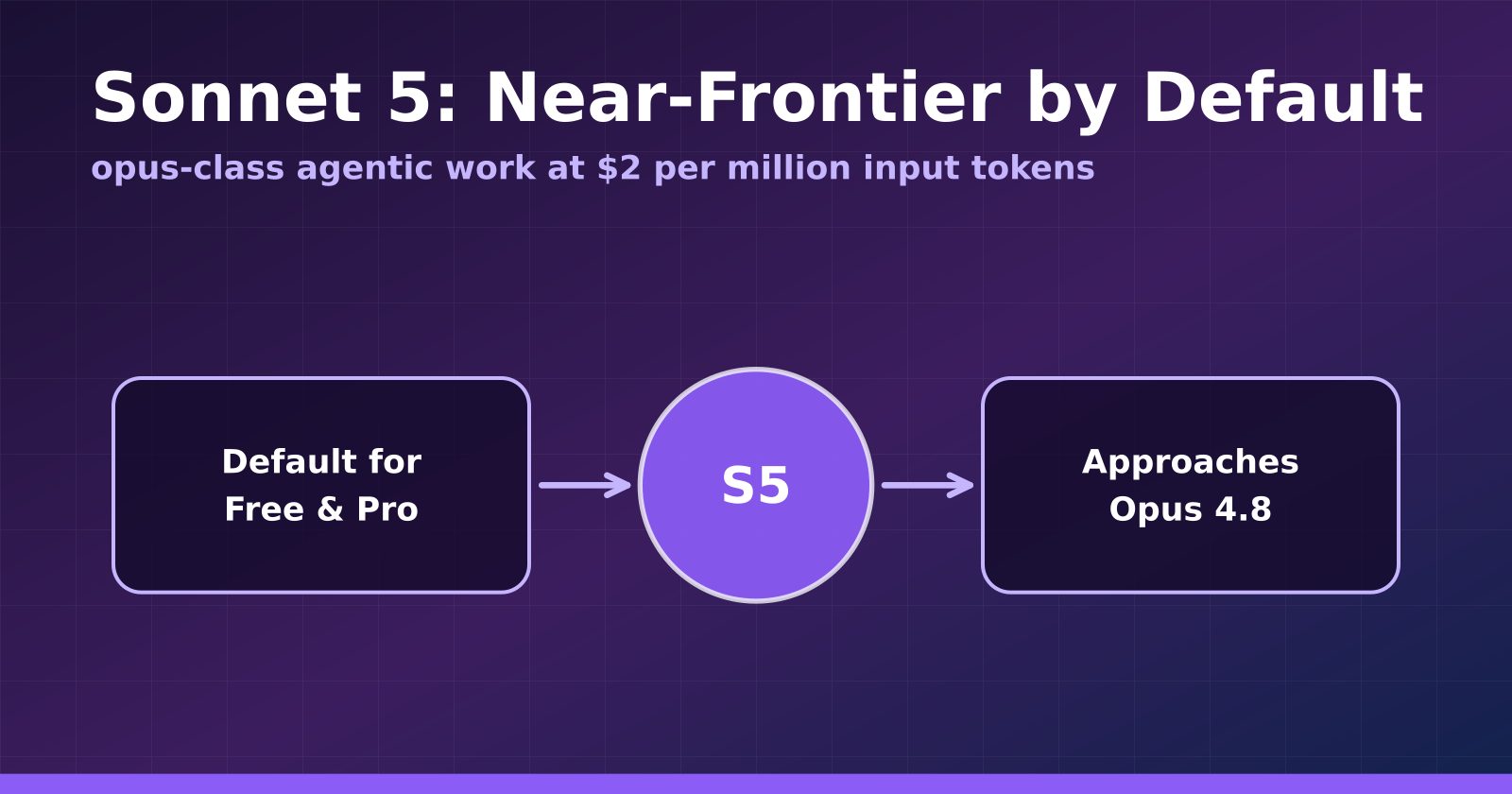
Claude Sonnet 5 Makes Near-Frontier Performance the Default Tier
Anthropic's Sonnet 5 launches at $2 per million input tokens, approaches Opus 4.8 on agentic benchmarks, and becomes the default for Free and Pro users.