Kỷ Nguyên 'Cost-per-Task': Khi Hiệu Quả Chi Phí Vượt Lên Kích Thước Mô Hình AI
Chào các bạn lập trình viên! Hôm nay chúng ta sẽ bàn về một sự dịch chuyển mang tính sống còn trong cách các doanh nghiệp đánh giá và triển khai ứng dụng AI trong thực tế.
Trong suốt 3 năm qua, cả thế giới công nghệ phát cuồng vì một câu hỏi duy nhất: "Mô hình của bạn có bao nhiêu tỷ tham số (parameters)?" Ai cũng mặc định rằng mô hình càng lớn thì càng tốt. Nhưng hiện nay, chỉ số thực tế quyết định tất cả là: Chi phí trên mỗi tác vụ - Cost-per-Task (CpT).
Nhận định cá nhân của tôi: Đây là điều tuyệt vời nhất xảy ra với ngành lập trình AI. Nó bắt buộc các nhà phát triển phải tư duy như một kiến trúc sư phần mềm thực thụ thay vì những học sinh thích nghịch công nghệ. Chúng ta hãy cùng mổ xẻ CpT và cách tối ưu chi phí vận hành AI.
Nền kinh tế "Cost-per-Task" là gì?
- Cạm bẫy lãng phí công suất (Overkill): Việc sử dụng một siêu mô hình lớn (như GPT-4o) chỉ để gắn tag email là "Yêu cầu hoàn tiền" hay "Lỗi kỹ thuật" cực kỳ lãng phí. Bạn trả $0.05 trong khi thực chất chỉ cần tiêu tốn $0.0001.
- Công thức CpT: Cost-per-Task đánh giá số tiền thực tế bạn phải chi ra để hoàn thành một kết quả đầu ra cụ thể (ví dụ: tóm tắt bài báo, trích xuất từ khóa).
Ứng dụng tư duy "Cost-per-Task" vào sản phẩm thực tế
Trong các ứng dụng web hiện đại, tư duy tối ưu hóa này cần được cài đặt trực tiếp:
- Làm sạch cục bộ (Local Cleaning): Dùng các bộ parser ở client để bóc tách toàn bộ script, CSS, và menu điều hướng ngay trong trình duyệt của người dùng (tiết kiệm điện toán server!).
- Loại bỏ ảnh trùng lặp: Xóa các ảnh thừa, dữ liệu trùng lặp trước khi gửi lên API.
- Giới hạn dung lượng: Cắt ngắn nội dung ở mức giới hạn ký tự tối đa để tránh bùng nổ chi phí gọi API.

(Kiến trúc tối ưu hóa chi phí và điều phối tác vụ AI thông minh)
Hướng dẫn kỹ thuật: Tối ưu hóa chi phí AI từng bước
- Triển khai kiến trúc định tuyến (Semantic Routing): Định tuyến câu hỏi dễ sang Llama 3 8B hoặc Claude Haiku, chỉ gọi GPT-4o cho các tác vụ suy luận cực khó.
- Fine-tune các mô hình nhỏ chuyên biệt: Dùng mô hình 7B hoặc 8B đã được fine-tune trên 1.000 ví dụ cụ thể của bạn thay vì dùng prompt dài trên mô hình lớn.
- Lưu trữ đệm ngữ nghĩa (Semantic Caching): Sử dụng các vector database để cache câu trả lời trùng lặp ngữ nghĩa.
Kinh nghiệm của bạn thế nào? Bạn đã từng cắt giảm thành công chi phí API AI bằng semantic routing hay lượng tử hóa mô hình chưa? Hãy chia sẻ bên dưới nhé!
Sẵn sàng sắp xếp tri thức với AI?
BrainMap tự động phân loại ghi chú, khám phá kết nối và xây dựng đồ thị tri thức cá nhân. Miễn phí — không cần thẻ tín dụng.
Dùng thử miễn phíBài viết liên quan
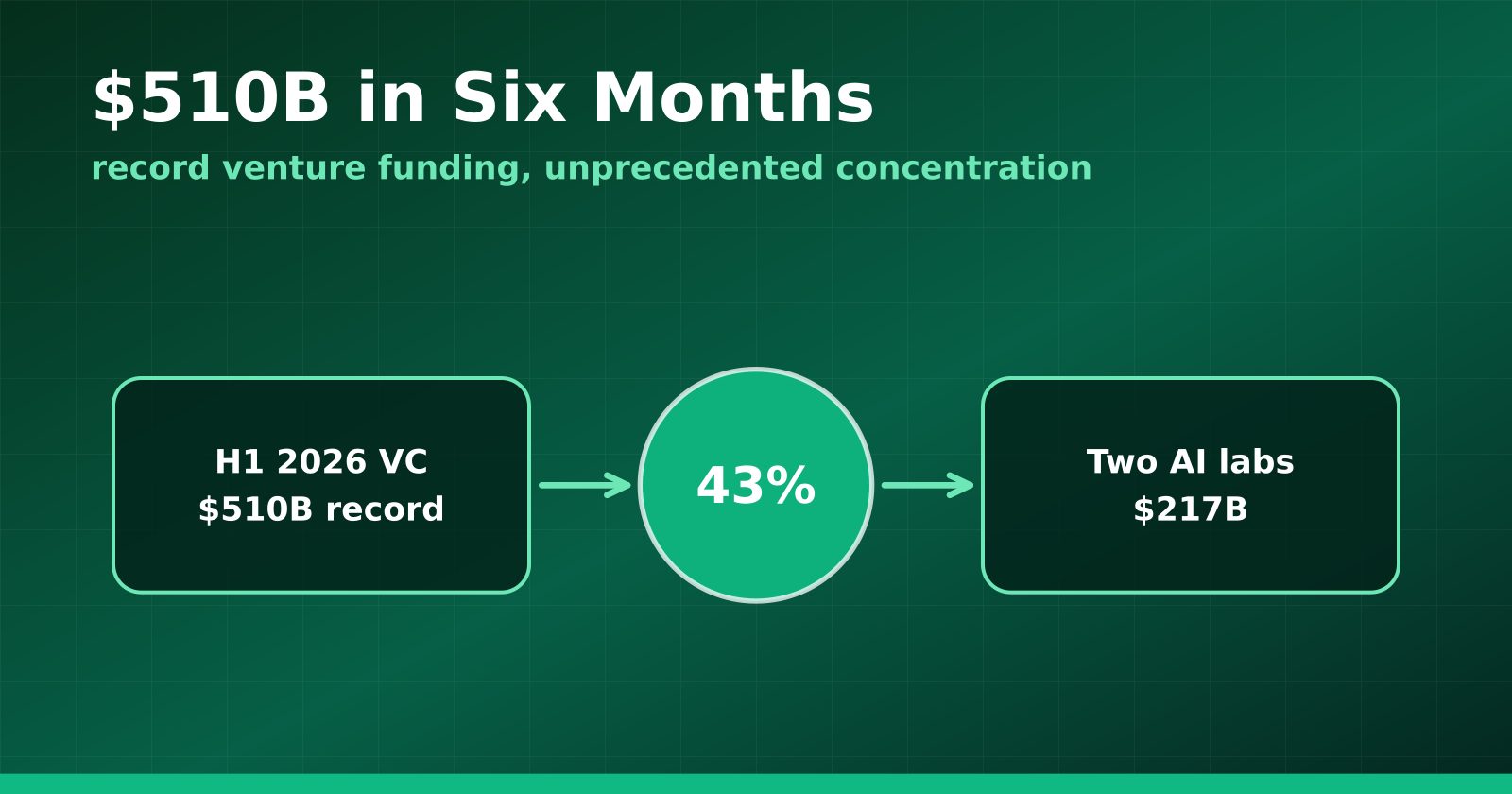
510 tỷ đô đổ vào startup nửa đầu 2026 — gần một nửa chảy về hai cái tên
Báo cáo bán niên của Crunchbase: vốn mạo hiểm toàn cầu lập đỉnh lịch sử, nhưng riêng OpenAI và Anthropic đã hút 217 tỷ đô, tức 43% tổng vốn của cả thế giới startup.
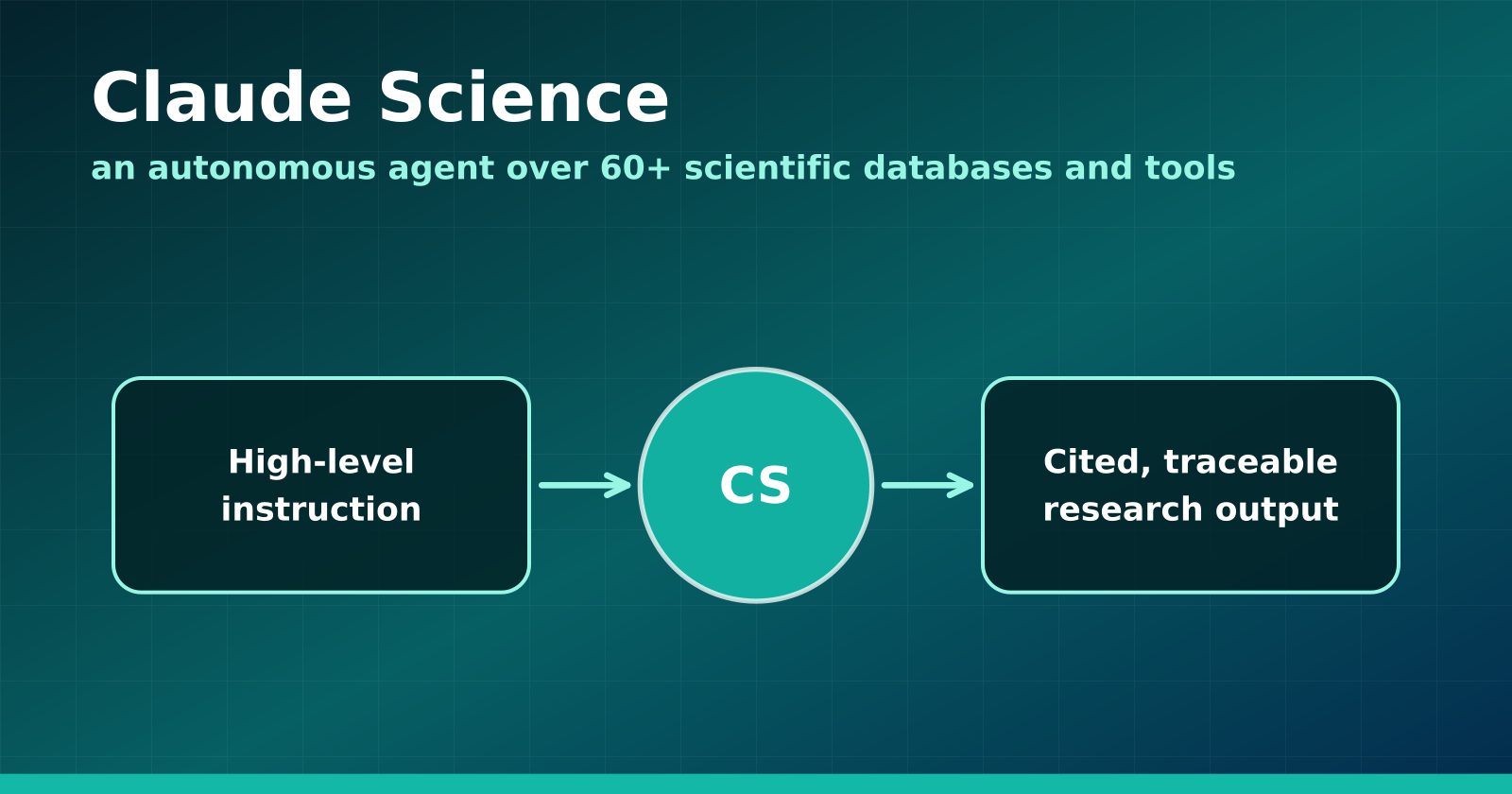
Claude Science: khi agent ngồi vào bàn làm việc của nhà khoa học
Sản phẩm chủ lực mới của Anthropic nối hơn 60 cơ sở dữ liệu khoa học vào một agent tự làm việc. Hãng còn tự dùng nó để đi tìm thuốc cho các bệnh hiếm.
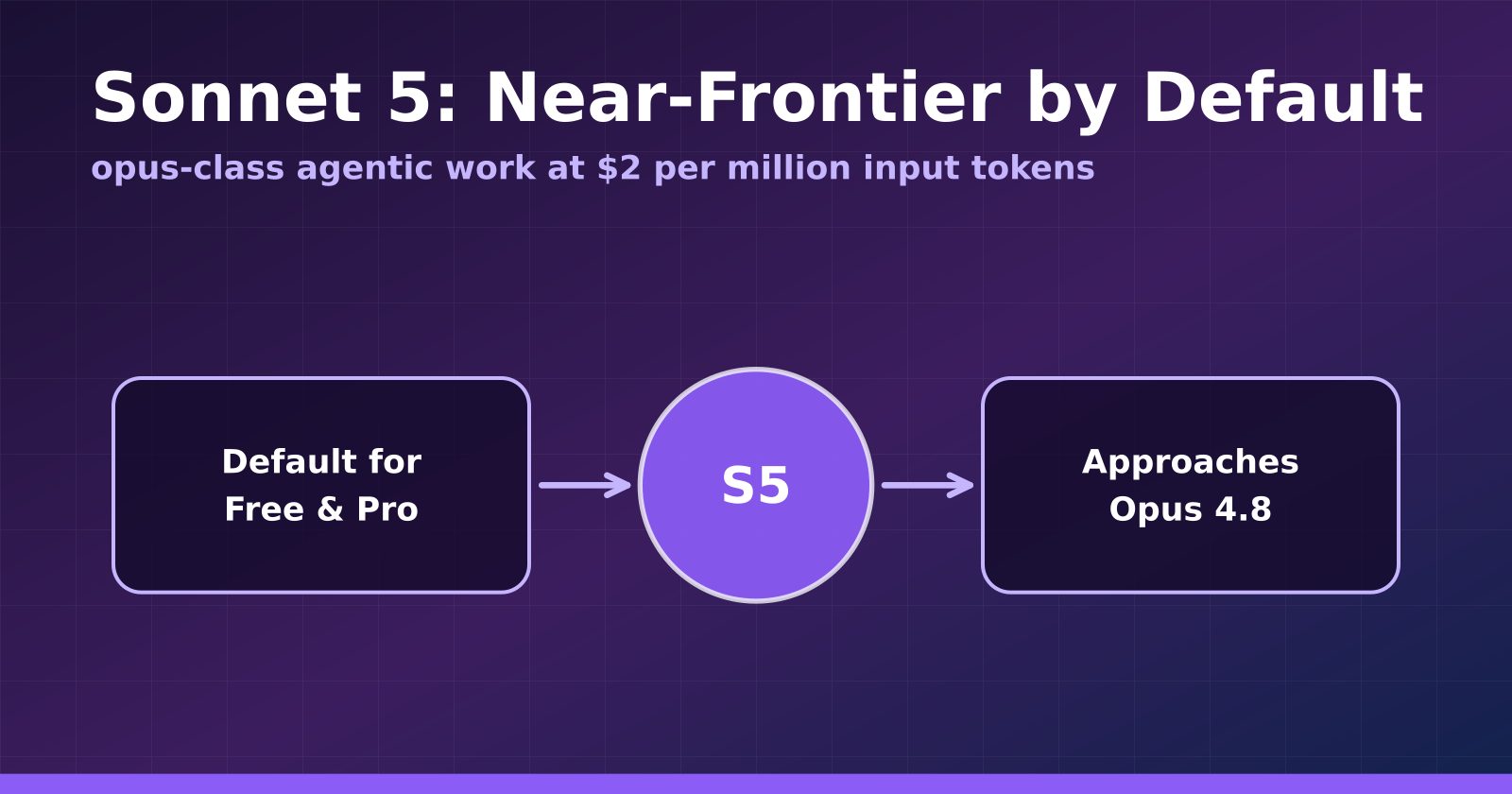
Claude Sonnet 5: mạnh gần bằng Opus, giá chỉ 2 đô
Anthropic vừa tung Sonnet 5 với sức mạnh tiệm cận Opus 4.8 nhưng giá khuyến mãi chỉ 2 đô mỗi triệu token. Người dùng Free và Pro được chuyển sang mô hình mới ngay lập tức.