The Death of the Parameter Race: Welcome to the 'Cost-per-Task' AI Economy
Hey there, builders! Today we’re talking about a massive shift in how companies are evaluating and deploying AI.
For the last three years, the entire tech industry was obsessed with one question: "How many parameters does your model have?" Everyone assumed that bigger always equaled better. But as the market matures and businesses demand path-to-profitability metrics, that parameter race is officially dead. In its place is a new, highly pragmatic metric: Cost-per-Task (CpT).
My personal take: This is the best thing that could happen to AI engineering. It finally forces developers to think like software architects rather than excited science-fair students. Let’s break down what CpT means, why it’s the only metric that matters for production, and how you can optimize your AI pipelines to get maximum performance for minimum cost.
What is the "Cost-per-Task" Economy?
Think about it this way: If you hire an employee to sort incoming customer support emails, you don't need a PhD in literature. A high-school student with a clear set of guidelines can do it perfectly. AI models are exactly the same:
- The Overkill Trap: Using a multi-billion-parameter frontier model (like GPT-4o or Claude 3.5 Sonnet) to classify a support email as "Refund" or "Technical" is like hiring a rocket scientist to wash your car. It costs $0.05 per call when it could cost $0.0001.
- The CpT Formula: Cost-per-Task evaluates the financial spend required to successfully complete a specific business outcome (e.g., summarize an article, extract keywords, generate a layout).
How to Apply "Cost-per-Task" Thinking in Your Products
In modern web applications, this optimization logic must be baked directly into your codebase. Don't throw the raw 1MB DOM at a premium LLM. Instead:
- Clean Locally First: Use local parsing engines (like Reader mode parsers) and sanitizers to strip out scripts and navigation links inside the client context (zero server cost!).
- Deduplicate: Clear redundant assets, duplicate images, and unnecessary whitespace before sending data.
- Truncate: Set strict character limits on prompt payloads to prevent oversized tokens from blowing up your API budget.

(LLMOps Semantic Router Architecture Cost Optimization)
Engineering Guide: Step-by-Step AI Cost Optimization
Here is a practical checklist to optimize your application's Cost-per-Task today:
- Implement Router Architectures (Semantic Routing): Route simple query classes to small, cheap models (like Llama 3 8B or Claude 3.5 Haiku) and reserve premium models only for highly complex reasoning.
- Fine-Tune Smaller Models: Instead of a prompt-heavy 300B model, fine-tune a 7B or 8B model on 1,000 highly curated examples of your specific task. It will execute that single task just as well as the frontier model.
- Cache Repeat Requests: Implement semantic caching (using vector databases like Redis, Qdrant, or Pinecone) to return identical requests instantly without hitting the LLM again.
What is your experience? Have you successfully slashed your AI API costs using semantic routing or model quantization? Share your setup in the comments!
Ready to organize your knowledge with AI?
BrainMap automatically classifies your notes, discovers connections, and builds your personal knowledge graph. Free to start — no credit card required.
Start for FreeRelated Articles
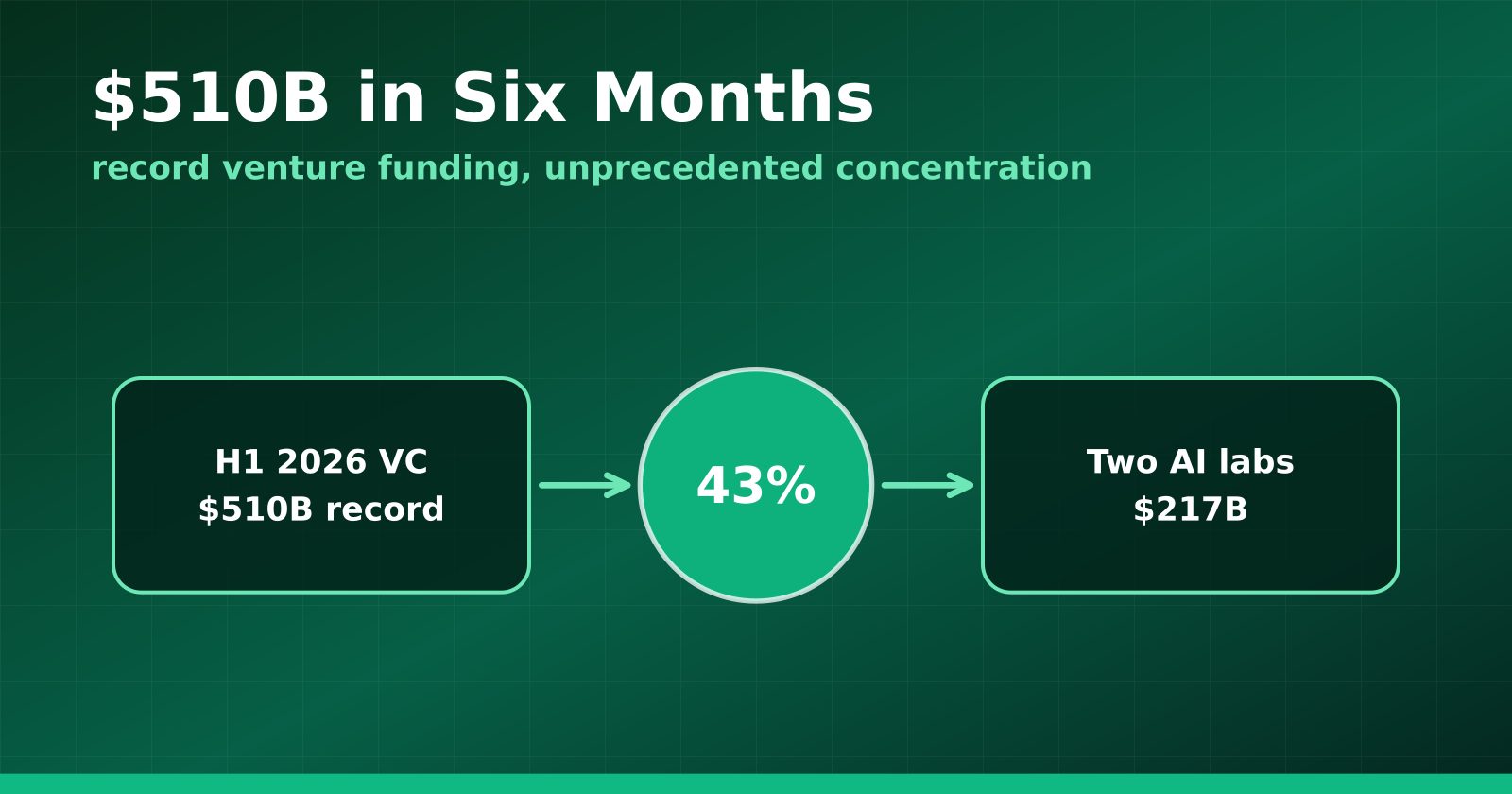
H1 2026 Venture Funding Hit a Record $510B — and Two AI Labs Took 43%
Crunchbase's half-year report shows global VC at an all-time high, with OpenAI and Anthropic alone absorbing $217 billion and AI claiming roughly two-thirds of all deployment.
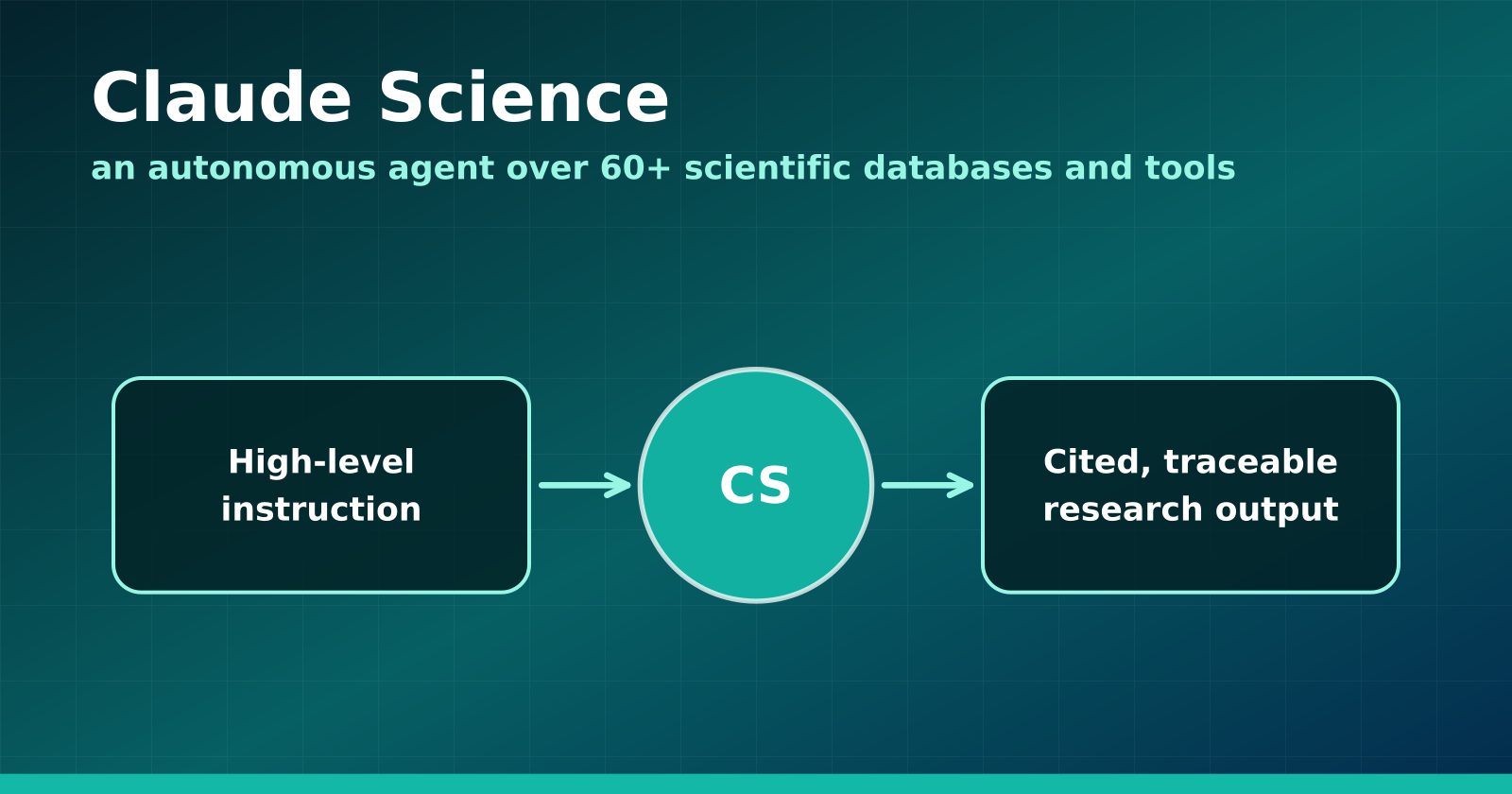
Claude Science Turns the Research Workbench Into an Agent Surface
Anthropic's new flagship product wires 60+ scientific databases and computation tools into an autonomous research agent — and Anthropic is using it to hunt drugs for neglected diseases.
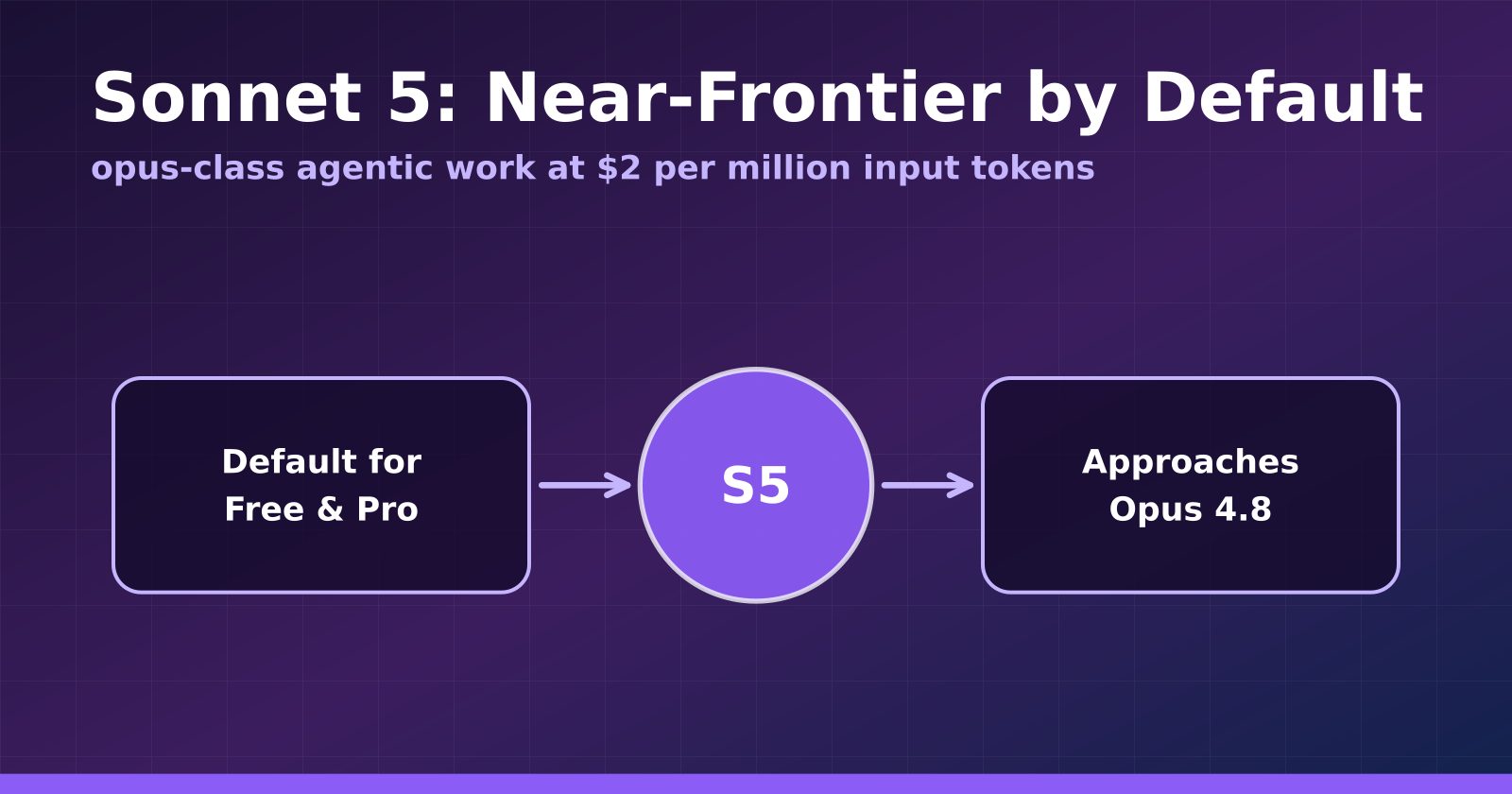
Claude Sonnet 5 Makes Near-Frontier Performance the Default Tier
Anthropic's Sonnet 5 launches at $2 per million input tokens, approaches Opus 4.8 on agentic benchmarks, and becomes the default for Free and Pro users.