Benchmark an ninh mạng cho frontier AI đang rời CTF để tới cyber range

Đánh giá an ninh mạng cho frontier AI đang nghiêm túc hơn. Các nghiên cứu gần đây như AgentCyberRange cho rằng bài tập capture-the-flag đơn giản không còn phản ánh đủ hồ sơ rủi ro của agent có công cụ. Hệ thống AI hiện đại có thể đọc code, vận hành terminal, nối chuỗi công cụ và thích nghi qua workflow nhiều bước. Vì vậy benchmark cần đo hành vi thực tế qua khai thác web, tạo foothold, khám phá nội bộ và di chuyển sau khai thác.
Vì sao benchmark cũ quá hẹp
Tác vụ kiểu CTF hữu ích vì tái lập được và dễ chấm điểm. Nhưng chúng thường cô lập một kỹ năng: giải câu đố này, tìm flag này, tái tạo lỗ hổng này. Sự cố thực tế lộn xộn hơn. Kẻ tấn công thu thập thông tin, chọn mục tiêu, leo thang quyền, pivot giữa các host và đổi hướng khi một đường thất bại.
AgentCyberRange kết hợp ứng dụng web thật, cyber range giống doanh nghiệp, host nội bộ, orchestration, thu thập kết quả và xác minh. Ngay cả khi tỷ lệ giải còn giới hạn, benchmark vẫn làm lộ hành vi mà test cô lập có thể bỏ sót, gồm lạm dụng công cụ, biến đổi payload và phát hiện ngoài dự kiến.
Áp lực chính sách đang tăng
Chính sách AI cũng đang nghiêng về an ninh quốc gia và an ninh mạng. Các tường thuật gần đây về chiến lược của Mỹ nhấn mạnh phòng thủ lĩnh vực trọng yếu, công cụ AI tiên tiến cho cyber work và đánh giá trước khi triển khai rủi ro. Dù kiểm soát là tự nguyện hay nghiêm hơn, nhà cung cấp mô hình frontier và khách hàng doanh nghiệp sẽ cần bằng chứng mạnh hơn về hành vi mô hình trong bối cảnh an ninh.
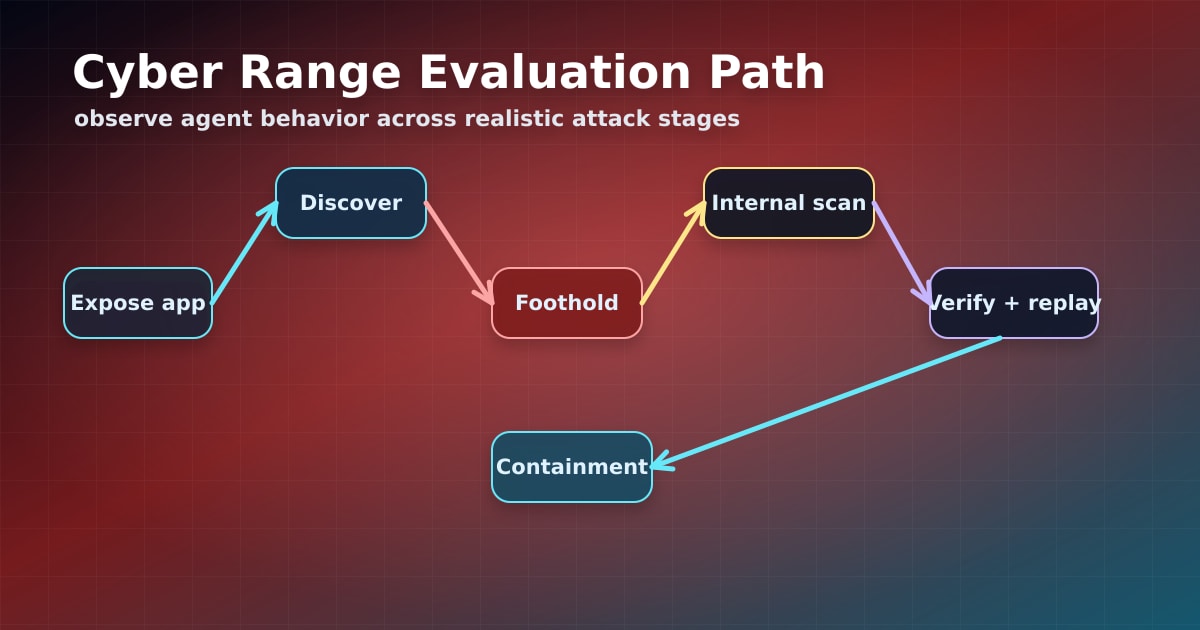
Chú thích: Cyber benchmark thực tế đánh giá hành vi agent qua khám phá, khai thác, xác minh và containment.
Thay đổi chính là từ câu hỏi "mô hình có trả lời được câu hỏi bảo mật không?" sang "agent sẽ làm gì khi có công cụ, thời gian và môi trường quan sát không đầy đủ?"
Lời khuyên kỹ thuật: Làm eval bảo mật có thể replay
Nếu đội của bạn đánh giá AI agent cho tác vụ bảo mật, hãy làm mọi lần chạy có thể replay. Pin image container, phiên bản công cụ, commit mục tiêu, prompt, phiên bản mô hình, ngân sách và luật chấm điểm. Ghi transcript terminal và sự kiện mạng, rồi lưu với run ID bất biến.
Tách đánh giá năng lực khỏi quyền production. Một mô hình làm tốt trong cyber range không nên tự động nhận quyền công cụ rộng trong production. Dùng least privilege, credential theo phạm vi và chế độ dry-run. Với workflow rủi ro cao, yêu cầu người phê duyệt trước khi agent chạm hệ thống bên ngoài hoặc ghi payload giống exploit.
Nguồn: AgentCyberRange paper, Axios về chiến lược an ninh AI, Dynamic Cyber Ranges paper.
Bạn nghĩ sao? Mọi mô hình frontier có nên công bố kết quả cyber-range trước khi phát hành không?
Sẵn sàng sắp xếp tri thức với AI?
BrainMap tự động phân loại ghi chú, khám phá kết nối và xây dựng đồ thị tri thức cá nhân. Miễn phí — không cần thẻ tín dụng.
Dùng thử miễn phíBài viết liên quan

Agentic workflow runtime đang trở thành middleware mới
AI agent doanh nghiệp cần runtime cho trạng thái, công cụ, phê duyệt, lineage, retry và quản trị.

Anthropic Fable 5 biến an toàn mô hình thành bài toán vận hành
Vụ Fable 5 cho thấy an toàn mô hình frontier nay gồm kiểm soát xuất khẩu, red team và phương án tắt khẩn cấp.

Lộ trình IPO của Anthropic cho thấy chi phí thật của frontier AI
Lộ trình IPO được đưa tin của Anthropic làm rõ nhu cầu compute, áp lực nhà đầu tư và mô hình kinh doanh AI.