Frontier AI Cyber Benchmarking Moves From CTFs to Realistic Ranges

Frontier AI cybersecurity evaluation is getting more serious. Recent research such as AgentCyberRange argues that simple capture-the-flag tasks no longer capture the full risk profile of tool-using agents. Modern AI systems can inspect code, operate terminals, chain tools, and adapt over multi-step workflows. That means benchmarks need to measure realistic behavior across web exploitation, foothold creation, internal discovery, and post-exploitation movement.
Why Old Benchmarks Are Too Narrow
CTF-style tasks are useful because they are reproducible and easy to score. But they often isolate one skill: solve this puzzle, find this flag, reproduce this vulnerability. Real incidents are messier. Attackers gather information, choose targets, escalate privileges, pivot between hosts, and adapt when a path fails.
AgentCyberRange combines real web applications, enterprise-like cyber ranges, internal hosts, orchestration, result collection, and verification. Even when solve rates remain limited, the benchmark surfaces behavior that isolated tests can miss, including tool misuse, payload mutation, and unexpected discoveries.
Policy Pressure Is Increasing
AI policy is also turning toward national and cyber security. Recent U.S. strategy coverage emphasizes critical-sector defense, advanced AI tools for cyber work, and evaluation before risky deployment. Whether those controls remain voluntary or become stricter, frontier model providers and enterprise buyers will need stronger evidence about model behavior in security-relevant settings.
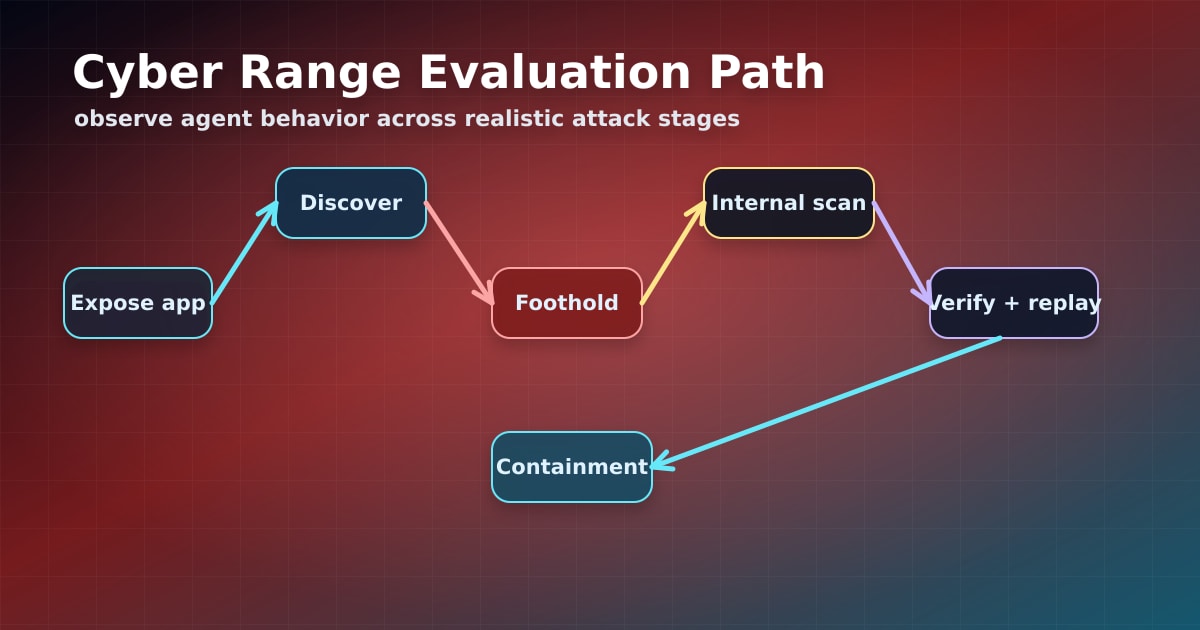
Caption: Realistic cyber benchmarks evaluate agent behavior across discovery, exploitation, verification, and containment.
The key shift is from "can the model answer a security question?" to "what does the agent do when it has tools, time, and a partially observable environment?"
Engineering Tip: Make Security Evals Replayable
If your team evaluates AI agents for security tasks, make every run replayable. Pin container images, tool versions, target commits, prompts, model versions, budgets, and scoring rules. Capture terminal transcripts and network events, then store them with immutable run IDs.
Separate capability evaluation from production permission. A model that performs well in a cyber range should not automatically receive broad tool access in production. Use least privilege, scoped credentials, and dry-run modes. For higher-risk workflows, require human approval before an agent touches external systems or writes exploit-like payloads.
Sources: AgentCyberRange paper, Axios on AI security strategy, Dynamic Cyber Ranges paper.
What do you think? Should every frontier model publish cyber-range evaluation results before release?
Ready to organize your knowledge with AI?
BrainMap automatically classifies your notes, discovers connections, and builds your personal knowledge graph. Free to start — no credit card required.
Start for FreeRelated Articles

Agentic Workflow Runtimes Are the New Middleware
Enterprise AI agents need runtimes for state, tools, approvals, lineage, retries, and governance.

Anthropic Fable 5 Turns Model Safety Into an Operations Problem
The Fable 5 dispute shows that frontier model safety now includes export controls, red teams, and operational shutdowns.

Anthropic's IPO Path Shows the Cost of Frontier AI Scale
Anthropic's reported IPO path highlights compute demand, investor pressure, and the business model behind frontier AI.