Gemini Live API Makes Real-Time Multimodal Apps Feel Native
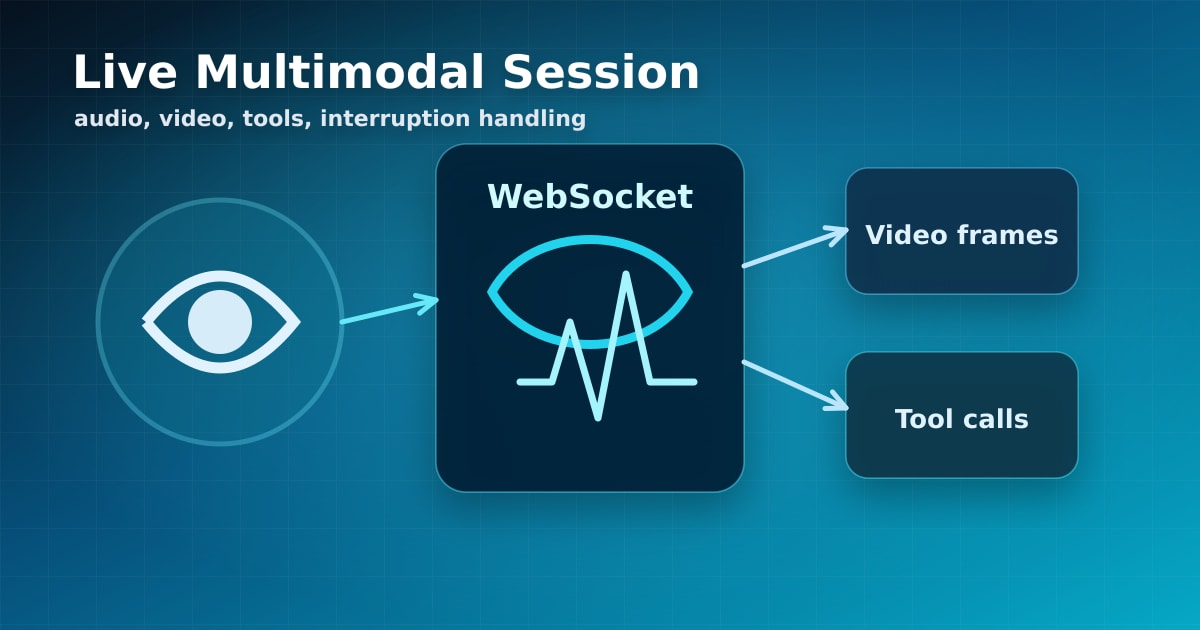
The Gemini Live API is one of the clearest signs that AI interfaces are moving beyond text boxes. Google's documentation describes a stateful, bidirectional WebSocket API for low-latency voice and video interactions with Gemini models. Instead of stitching together speech-to-text, a text model, and text-to-speech, developers can build sessions that handle audio, video, text, transcripts, tool calls, and interruptions in one loop.
What Changes for App Design
Live AI feels different because it has timing pressure. A normal chat interface can wait for a complete response. A voice agent has to handle barge-in, partial context, silence, background noise, device permissions, and user impatience. The Gemini Live API supports continuous input streams and model output that can include audio and text, which makes it a better fit for tutors, support agents, accessibility tools, and hands-free workflows.
Google's enterprise documentation also highlights native audio, voice activity detection, affective dialog, tool use, and transcription support. Those capabilities shift the design target from "send prompt, receive answer" to "maintain a session."
Stateful Sessions Need Strong Boundaries
A live session is not just a transport connection. It is an evolving context that may contain user speech, screen frames, tool results, and policy decisions. That means product teams need to think about retention, consent, redaction, and failure recovery before they add a microphone button.
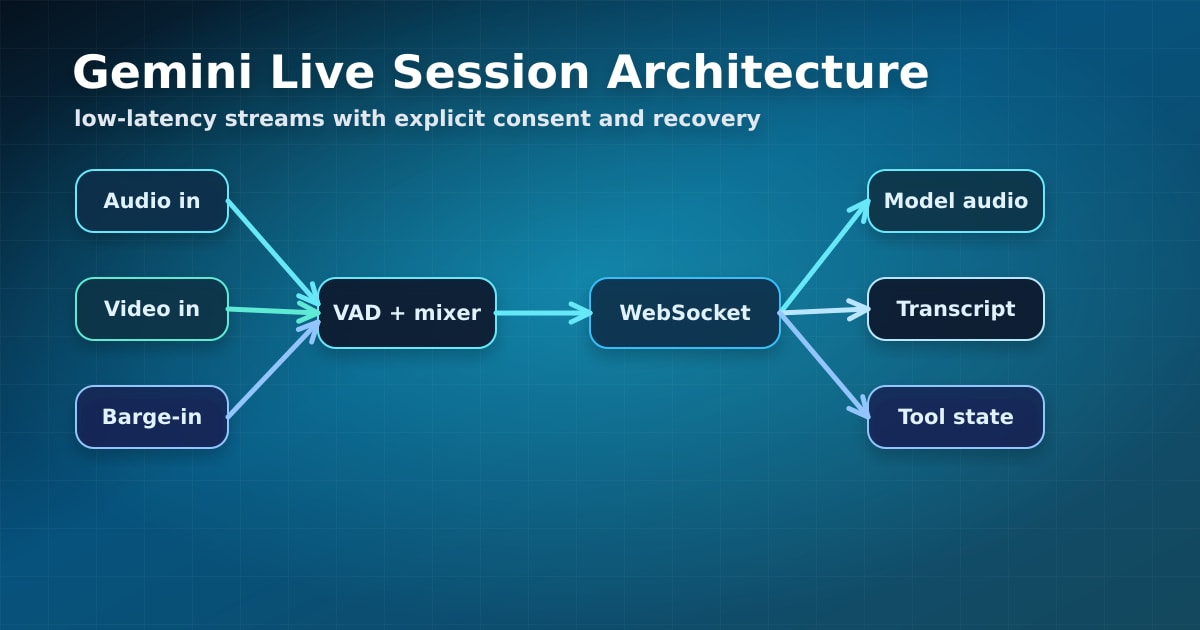
Caption: A live multimodal session coordinates audio, video, text, tools, transcripts, and policy checks.
The best experiences will feel instant to users while staying conservative with sensitive inputs.
Engineering Tip: Build a Reconnectable Session Layer
Wrap the Live API connection in your own session manager. Track connection state, input device state, transcript state, tool-call state, and user consent separately. If the WebSocket drops, your app should be able to resume gracefully, summarize recent context, or restart with a clear user-facing state.
For browser apps, isolate microphone capture, audio playback, and model transport into separate modules. Add backpressure controls so video frames do not overwhelm the session. Store transcripts only after an explicit product decision, and redact sensitive fields before sending them to analytics or logs.
Sources: Gemini Live API Reference, Firebase AI Logic Live API, Google Cloud Live API Docs.
What do you think? Which apps should become voice-first now that live multimodal APIs are practical?
Ready to organize your knowledge with AI?
BrainMap automatically classifies your notes, discovers connections, and builds your personal knowledge graph. Free to start — no credit card required.
Start for FreeRelated Articles

Agentic Workflow Runtimes Are the New Middleware
Enterprise AI agents need runtimes for state, tools, approvals, lineage, retries, and governance.

Anthropic Fable 5 Turns Model Safety Into an Operations Problem
The Fable 5 dispute shows that frontier model safety now includes export controls, red teams, and operational shutdowns.

Anthropic's IPO Path Shows the Cost of Frontier AI Scale
Anthropic's reported IPO path highlights compute demand, investor pressure, and the business model behind frontier AI.