Gemma 4 Makes Local-First AI Feel Practical Again
Gemma 4 is a strong signal for local-first AI. Google's model card describes a family of open models from Google DeepMind with multimodal inputs, dense and mixture-of-experts variants, configurable reasoning modes, long context windows, and Apache 2.0 licensing. For builders of note-taking tools, education apps, developer utilities, and private enterprise workflows, that combination changes the product calculus.
Local AI Is About Control, Not Nostalgia
Running a model locally is not only about avoiding API bills. It gives users and organizations more control over latency, privacy, availability, and data movement. A local model can classify notes on a laptop, summarize documents on a workstation, or provide coding assistance inside a secure environment without sending every artifact to a hosted provider.
Gemma 4's range of model sizes matters because local-first is not one hardware target. A phone, a student laptop, a workstation, and an internal server all have different memory and latency limits.
The Product Pattern: Cloud When Needed, Local By Default
The best near-term architecture is hybrid. Use local models for high-frequency, privacy-sensitive, or low-latency tasks. Route only harder tasks to cloud models when the user approves or when policy allows it. That pattern can reduce cost while making the product feel faster and more trustworthy.
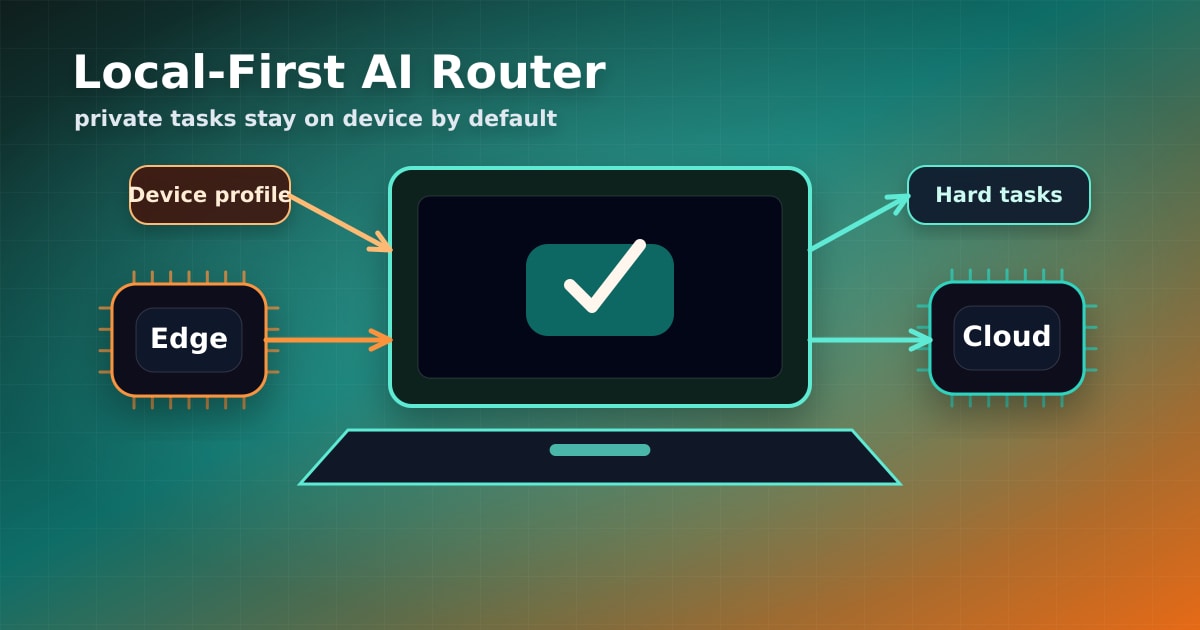
Caption: A local-first AI app can classify, retrieve, and summarize privately before escalating difficult work to the cloud.
For BrainMap-style knowledge tools, local embeddings, note clustering, draft summaries, and offline search are especially good candidates.
Engineering Tip: Treat Local Models as Variable Capability
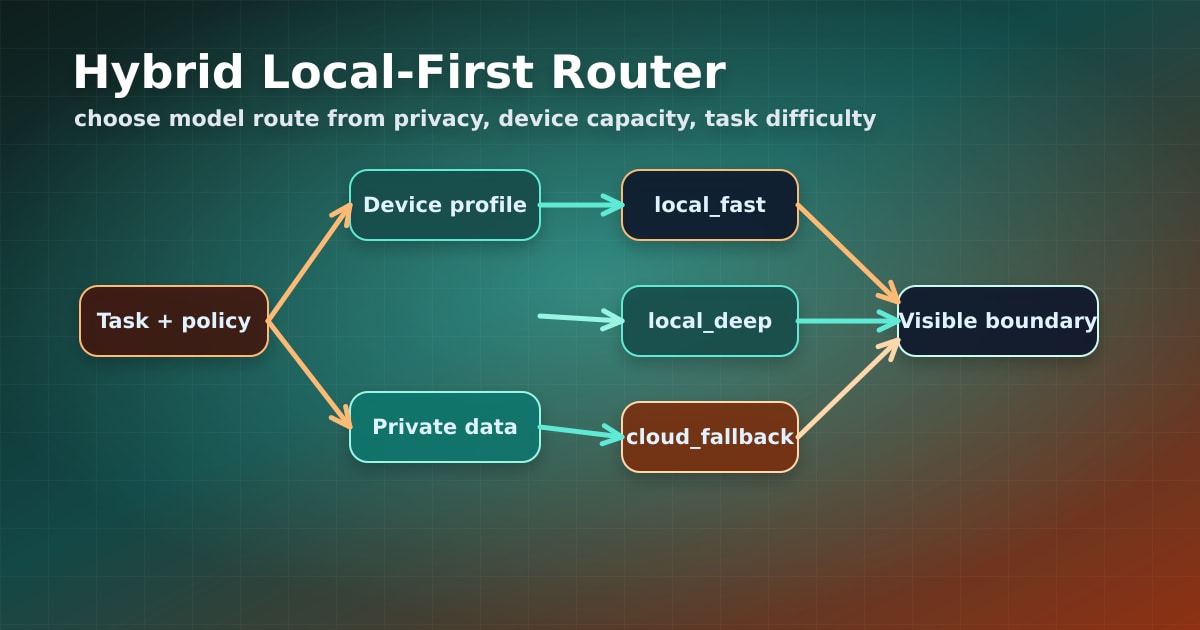
Do not assume every device can run the same model. Build a capability detector that measures memory, accelerator availability, model load time, and tokens per second. Choose model size and quantization based on that profile.
Add a task router with explicit quality tiers: local_fast, local_deep, cloud_fallback, and manual_review. Cache local outputs with a content hash and model version so the app can safely reuse work after restarts. Most importantly, tell users when data stays local and when it leaves the device. Local-first only builds trust if the boundary is visible.
Sources: Gemma 4 Model Card, Gemma 4 Launch Blog, Gemma Documentation.
What do you think? Which AI features should always run locally, even if a cloud model would be slightly smarter?
Ready to organize your knowledge with AI?
BrainMap automatically classifies your notes, discovers connections, and builds your personal knowledge graph. Free to start — no credit card required.
Start for FreeRelated Articles

Agentic Workflow Runtimes Are the New Middleware
Enterprise AI agents need runtimes for state, tools, approvals, lineage, retries, and governance.

Anthropic Fable 5 Turns Model Safety Into an Operations Problem
The Fable 5 dispute shows that frontier model safety now includes export controls, red teams, and operational shutdowns.

Anthropic's IPO Path Shows the Cost of Frontier AI Scale
Anthropic's reported IPO path highlights compute demand, investor pressure, and the business model behind frontier AI.