Mapping the Mind: Inside Meta's TRIBE v2, the Tri-Modal Digital Twin of the Human Brain

Hello friends! Today, we are taking a leap into the cutting edge of biological and artificial intelligence convergence: Meta AI’s open release of TRIBE v2.
Imagine a computer model so advanced that it acts as a population-level simulator of human neural activity. Trained on large-scale fMRI (functional Magnetic Resonance Imaging) data, TRIBE v2 is a tri-modal foundation model that takes in text, video, and audio, then predicts average brain-response patterns on a cortical mesh.
But let's look at this critically: Are we genuinely mapping the human mind, or are we just building a highly advanced digital caricature of neural patterns that lacks true cognitive comprehension? Let’s unpack this incredible scientific milestone and see how we can apply its architectural principles to multi-modal system designs.
Under the Hood: How TRIBE v2 Connects Senses to Silicon
Most AI models we use today are single-modal (text-only) or bi-modal (text and image). They treat inputs as abstract mathematical vectors. TRIBE v2 is unique because it bridges three sensory inputs (Text, Video, Audio) and maps them to a biological target:
- The Tri-Modal Encoder: Video frames, audio waves, and textual descriptions are processed through unified transformers, creating a cohesive sensory representation.
- fMRI Neural Mapping: The model projects these sensory vectors into a high-dimensional space aligned with voxel-level coordinates of human brain regions (visual cortex, auditory cortex, and language centers).
- The Simulator Effect: Scientists can feed a new movie clip, and the model estimates how an average subject's brain regions would respond—potentially reducing the number of costly exploratory fMRI experiments.
(Human fMRI Brain Activity Voxel Neural Map Simulation)
Engineering Guide: How to Conceptualize Multi-Modal Architectures
While we might not be training fMRI models, we can borrow the core architectural patterns of TRIBE v2 to build highly responsive, multi-sensory applications:
- Adopt a Unified Vector Space (Embeddings): If you are building a search system or content aggregator, don't just index text. Generate unified embeddings using models that support multi-modal mapping (like OpenAI's CLIP or Google's Gemini Embeddings). This allows users to search text and retrieve matching images/audio instantly.
- Implement Temporal Syncing: When handling video or rich web content, ensure your data structures bind text annotations, audio events, and visual frames to a single timeline coordinate.
- Use Safe DOM Extraction for Multi-Modal Elements: When extracting content from web pages, proactively capture meta tags for
og:image, video sources, and alternative image descriptions (altattributes). Build a cohesive multi-modal payload so that downstream LLMs have full context of what the user is looking at.
Source: Meta TRIBE v2 model card.
What is your perspective? Will brain-simulation models like TRIBE v2 unlock true Artificial General Intelligence (AGI), or is neuroscience the wrong path to advanced AI? Let's discuss in the comments below!
Ready to organize your knowledge with AI?
BrainMap automatically classifies your notes, discovers connections, and builds your personal knowledge graph. Free to start — no credit card required.
Start for FreeRelated Articles
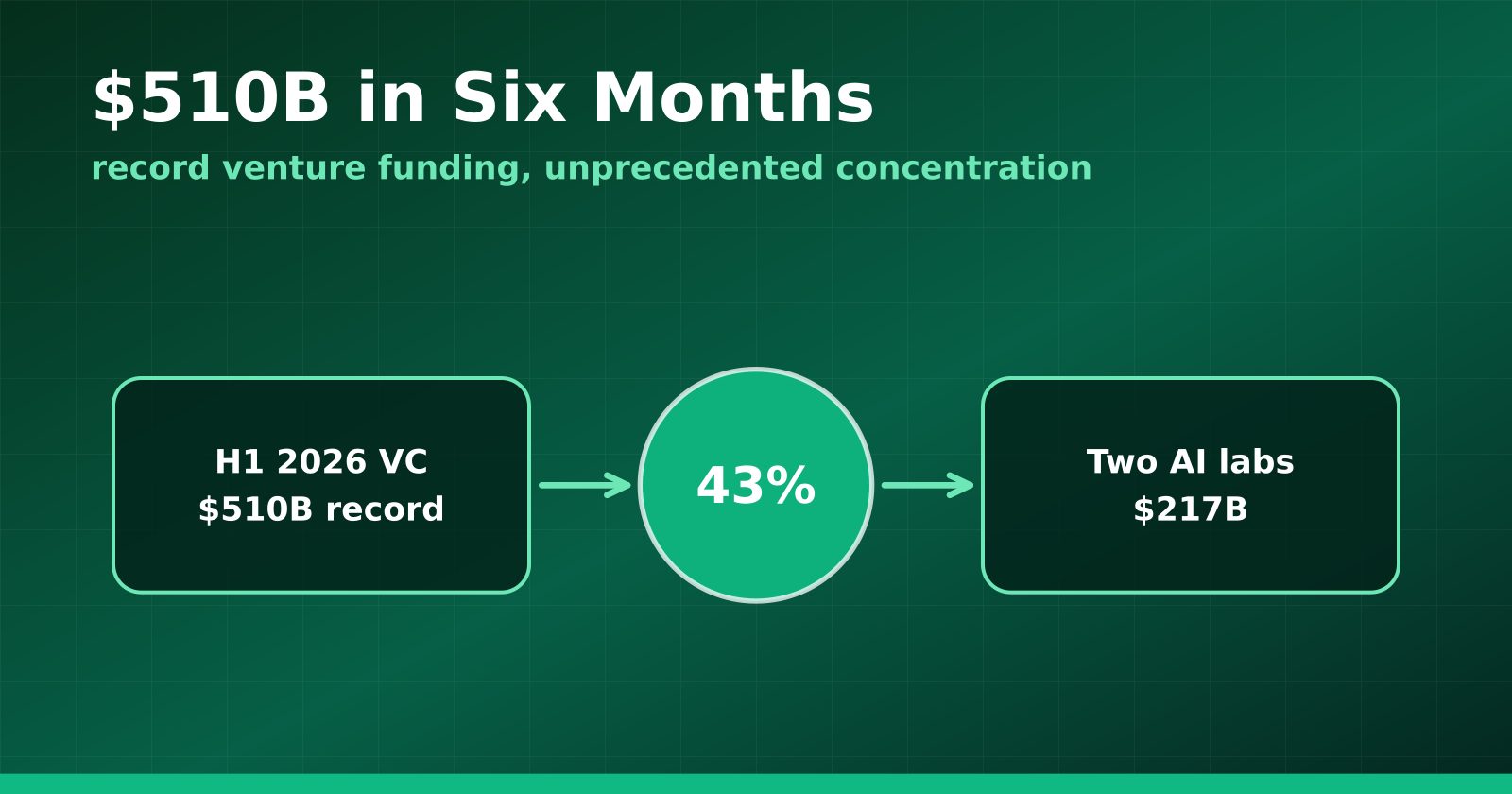
H1 2026 Venture Funding Hit a Record $510B — and Two AI Labs Took 43%
Crunchbase's half-year report shows global VC at an all-time high, with OpenAI and Anthropic alone absorbing $217 billion and AI claiming roughly two-thirds of all deployment.
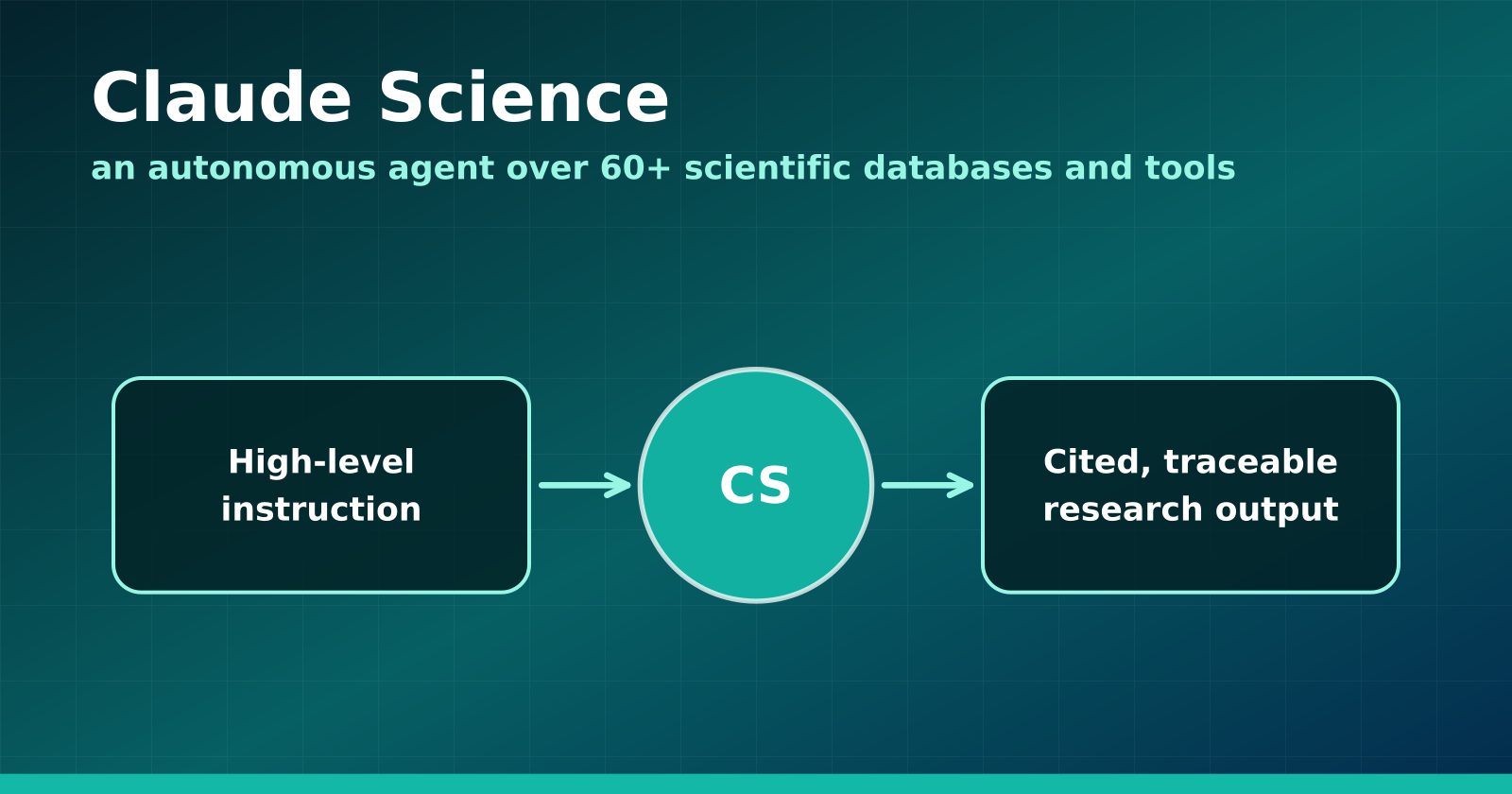
Claude Science Turns the Research Workbench Into an Agent Surface
Anthropic's new flagship product wires 60+ scientific databases and computation tools into an autonomous research agent — and Anthropic is using it to hunt drugs for neglected diseases.
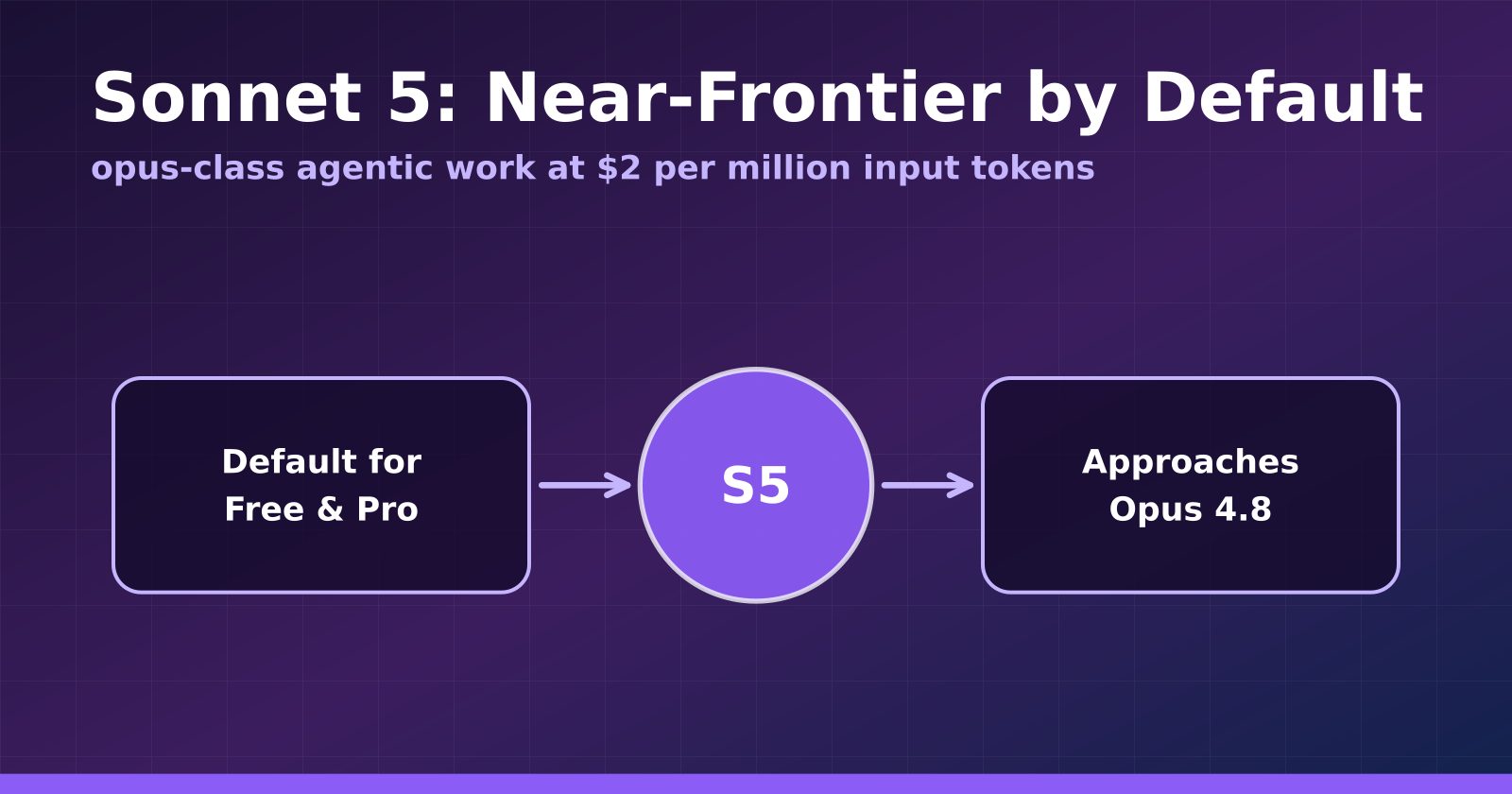
Claude Sonnet 5 Makes Near-Frontier Performance the Default Tier
Anthropic's Sonnet 5 launches at $2 per million input tokens, approaches Opus 4.8 on agentic benchmarks, and becomes the default for Free and Pro users.