Starcloud and the Case for Space-Based AI Compute

Space-based compute sounds like science fiction until you look at the AI data-center problem: power demand, cooling, land constraints, permitting, carbon pressure, and network growth. Starcloud and other orbital data-center efforts are exploring whether satellites can host meaningful AI workloads by using abundant solar energy, radiative cooling, and increasingly cheaper launch capacity.
Why Orbit Is Attractive
In low Earth orbit, solar exposure can be more predictable than many terrestrial sites, and heat can be radiated into space without water-hungry cooling systems. For some workloads, especially data generated in orbit or delay-tolerant batch processing, putting compute near the sensor or near the power source may make architectural sense.
Starcloud's reported plans, including GPU-equipped satellites and larger constellation ambitions, show how quickly the idea has moved from whiteboard to prototype. The broader industry is also watching Google, SpaceX, Blue Origin, and startups explore space-based data-center concepts.
The Hard Constraints Are Still Hard
Orbital compute has brutal engineering constraints. Launch mass is expensive. Radiation can damage electronics. Thermal design is difficult. Hardware repairs are almost impossible. Networking must handle intermittent links, ground-station bottlenecks, and latency that is unacceptable for many interactive applications.
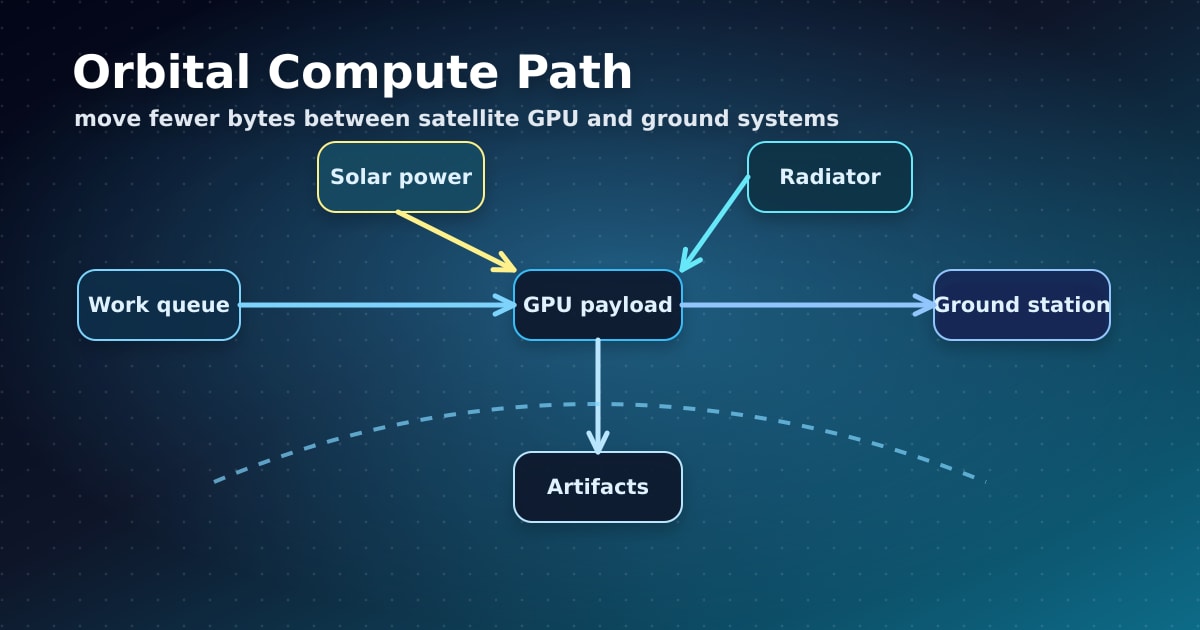
Caption: Space compute must balance solar power, thermal radiation, onboard GPUs, ground links, and workload scheduling.
That means space compute will not replace normal cloud regions. It is more likely to start with specialized workloads: Earth-observation inference, in-orbit data reduction, delay-tolerant AI jobs, and experiments that benefit from solar power economics.
Engineering Tip: Design for Delay-Tolerant Workloads
If you are evaluating orbital or remote compute, start by classifying workloads by latency tolerance and data gravity. Avoid interactive user flows. Favor batch inference, sensor pre-processing, model evaluation, compression, and summarization tasks where minutes of delay are acceptable.
Use store-and-forward queues, content-addressed artifacts, resumable uploads, and idempotent jobs. Assume links fail and results arrive late. Put strict size budgets on inputs and outputs, because downlink bandwidth can become the real bottleneck. The winning architecture will be the one that moves fewer bytes, not the one that runs the flashiest model.
Sources: Starcloud, The Times, SpaceNews.
What do you think? Which AI workloads would you trust to run in orbit first?
Ready to organize your knowledge with AI?
BrainMap automatically classifies your notes, discovers connections, and builds your personal knowledge graph. Free to start — no credit card required.
Start for FreeRelated Articles

Agentic Workflow Runtimes Are the New Middleware
Enterprise AI agents need runtimes for state, tools, approvals, lineage, retries, and governance.

Anthropic Fable 5 Turns Model Safety Into an Operations Problem
The Fable 5 dispute shows that frontier model safety now includes export controls, red teams, and operational shutdowns.

Anthropic's IPO Path Shows the Cost of Frontier AI Scale
Anthropic's reported IPO path highlights compute demand, investor pressure, and the business model behind frontier AI.